Anthropic内部95%业务分析交给Claude,秘诀竟然不在更强模型
Anthropic内部95%业务分析交给Claude,秘诀竟然不在更强模型
让AI查数据,它答得头头是道,你却不敢信。
刚刚,这个让无数搞AI数据分析的人最头疼的事,Anthropic给出了自己的解法,还在官方博客甩出两个95%的数字:
公司内部95%的业务分析查询,已由Claude自动完成;
整体准确率约95%。

https://claude.com/blog/how-anthropic-enables-self-service-data-analytics-with-claude?utm_source=chatgpt.com
这篇博客直指AI数据查询的核心痛点:答案看着对,却不敢轻易相信,不知哪里可能埋了雷。
Anthropic官方还为这种情况起了个名,叫「虚假的精确感」(false sense of precision):
把Claude直接接上数据仓库放手让它跑,它可能会回复你一个格式漂亮、语气笃定,却悄悄用错了表的答案。
这篇博客的作者来自Anthropic数据科学与数据工程团队,把重复机械的取数活交给Claude后,他们腾出手,去做因果建模、预测、机器学习等事情。
他们在博客中提到的最反常识的一个观点就是:让模型准确查数,最难的根本不在写SQL。
结构化查询语言(SQL)就是跟数据库要数据用的语言,过去会写它,是数据分析的一道门槛。
可对今天的大模型来说,把人话翻成SQL早已不是主要瓶颈,真正难的是在写SQL之前那一步。
三类常见错误,数据本身是一笔「糊涂账」
Anthropic认为数据分析,难就难在:数据本身是一笔「糊涂账」。
同一个问题,常常能对上好几份长得差不多的数据,到底该用哪一份,说不清。
AI真正要做对的,是从这一堆数据中挑出你要找的那份。这一步搞对了,后面写SQL把数取出来,几乎是顺理成章的事。
Anthropic将模型分析数据出错的主要原因,归为如下三类。

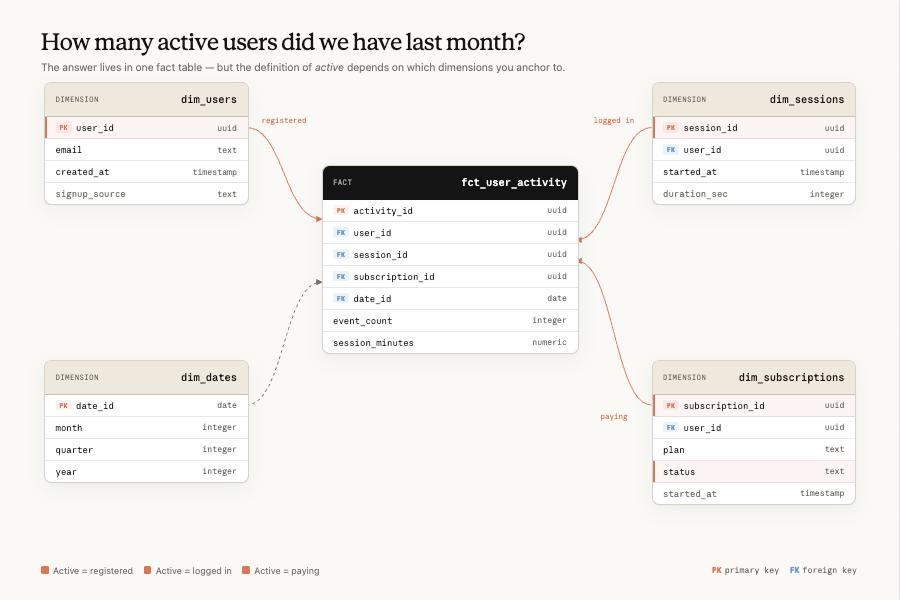
分析类AI的真正难点,是把用户问题映射到正确且最新的数据实体。
第一类,概念和实体对不上。
一个数据模型里有几百个看着都能用的字段,背后可能藏着上百万个。你问「有多少活跃用户」,什么动作算活跃?算不算欺诈账号?回溯窗口取7天还是30天?模型在这堆近义选项里,挑不出对的那个。
第二类,数据过时。
数据源、业务定义、表结构天天在变。模型脑子里的知识慢慢「生锈」,开始返回「细微处出错」的答案。这种错最难发现,看着全对,其实早就不对了。
第三类,检索失败。
信息其实就躺在模型里,标注也完整。可搜索空间太大,它压根没翻到。
把它和写代码对比,差别一下就清楚了。写代码是开放题,文档和单元测试天然挡着幻觉。数据分析往往只有一个正确答案、一个正确来源,而且没有任何确定性的办法证明它对。
所以Anthropic的结论是:分析的准确率,是上下文和验证的问题,并非模型会不会写代码的问题。
从21%到95%,Anthropic在中间做了什么
为了解决这三类错误,Anthropic搭了一套东西,起名叫智能体分析栈(agentic analytics stack),一共四层,每层专治一类问题。

Anthropic智能体分析栈结构图:数据基础层、事实来源、技能、验证四层各司其职。
第一层,数据基础层(data foundations):数据仓库本身,包括数据模型、转换、测试、表,以及描述它们的元数据。核心动作是把同一个概念收敛到唯一一张权威表,专治「概念-实体歧义」,同时也构建了预防数据口径过时的第一道工程防线。
Anthropic强调,维度建模等传统数据工程手艺,在AI时代同样关键。
第二层,事实来源(sources of truth):模型查数时参照的几个权威来源,按可信度从高到低是:语义层>血缘与转换图>查询语料>业务上下文。它的作用就是把用户嘴里模糊的问法,翻译成系统里唯一正确、有人维护的数据口径。
前两层合起来,专门解决「概念对不上」的痛点。
第三层,技能(Skills):把资深分析师的查询流程固化成可复用的模块,主治「检索失败」,保证模型可靠地找到、并用对那个答案。
第四层,验证(validation):离线评测、消融实验、在线验证,再加上维护流程,查出三类错里还有哪一类在漏,也是对抗「数据过时」的主要方式。
在搭这几层的过程里,Anthropic还撞见了两个反直觉的结果。
一个是偷懒的代价。
他们试过让大模型自动从原始表生成指标定义,结果生成的定义把想消除的歧义又原样编码了回去,在评测里直接成了负分。最后只能改回老办法:Claude起草文档,定义由人来拍板。
另一个更出乎意料。把几千条历史SQL直接喂给模型检索,准确率只提升了不到1个百分点。
这四层里,Anthropic披露的最大准确率跃迁来自Skills。
事实来源是声明式知识,告诉模型每个指标是什么意思;Skills是程序性知识,告诉它先查哪、按什么顺序查、一份合格分析长什么样。
形态上,Skills就是一个装着SKILL.md和说明、脚本、资源的文件夹,Claude按需读取。这个机制在Anthropic官方文档和GitHub仓库中都能交叉印证。
效果有多惊人?

根据Anthropic内部披露数字,没有Skills,Claude在内部评测里的准确率不超过21%;加上Skills之后,稳定冲到95%以上,部分领域接近99%。
从21%到95%,差的不是更强的模型,是这套结构。
95%的数字背后,这套东西「会腐烂」
但95%的准确率,并没有保持太久。
Anthropic发现,这套系统会过期:他们眼睁睁看着离线准确率,一个月内从约95%掉到约65%。
背后原因是,数据模型每天都在变,描述它的Skill文档没人管,因此几周后它就开始说错话。
于是Anthropic团队就把维护当成正经工程来做:Skill文档和数据模型塞进同一个代码仓库,改模型的那个代码合并请求(PR),顺手把对应文档也改了。现在约90%的数据模型改动,都带着一处Skill更新一起提交。
他们还做过一个负面实验。
给智能体开了全文检索(grep)权限,让它去翻历史SQL文件,还在运行记录里确认它确实一条条读了。结果准确率上下波动不到1个点。更要命的是,答错的那些题里,约80%的正确答案,其实就躺在它刚读过的语料里。它看见了,还是没用上。
那一刻Anthropic想明白了:真正的瓶颈是结构,不是拿不拿得到资料。这个判断,直接改写了他们之后几个月的路线图。
找对结构,能把准确率顶到一个高度。可最后那几个百分点,得拿真金白银去换。
比如,加一道对抗式审查(adversarial review),让模型反复死磕自己的假设,评测准确率能再涨6%。代价是token多烧32%,延迟高72%。
95%不是搭出来的,是养出来的。一旦松手,几周就可能塌回去。
参考资料:
https://claude.com/blog/how-anthropic-enables-self-service-data-analytics-with-claude
本文来自微信公众号“新智元”,作者:ASI启示录,36氪经授权发布。
来源:36氪
免责声明:含第三方意见,不构成财务建议
戴尔股价年内涨幅达 230%,Seeking Alpha 探讨估值是否过高
25 分钟前
博通与Ciena指引不及预期致科技股下挫,博通股价暴跌13%
29 分钟前谷歌实验室推出实验性应用 Dreambeans,整合 Gmail 等数据生成个性化故事
32 分钟前苹果新版 Siri 或借助谷歌云端的 Nvidia Blackwell B200 GPU 运行
35 分钟前Anthropic Claude Mythos 技术预览版遭未授权访问,安全基础设施成 AI 防御关键
41 分钟前英伟达开源 5500 亿参数 Nemotron 3 Ultra 模型,采用 Mamba-Transformer 混合 MoE 架构
46 分钟前Snap 收购增强现实公司 Illumix 以强化 AR 技术布局
2 小时前