95% of Anthropic's internal business analytics powered by Claude—surprising secret isn't stronger models
95% of Anthropic's internal business analytics powered by Claude—surprising secret isn't stronger models
Let AI query data, and it answers with confidence—but you can't trust it.
Just now, the most frustrating challenge for countless AI-driven data analysts has been addressed by Anthropic, who unveiled their solution in an official blog post featuring two 95% figures:
95% of internal business analytics queries at the company are now automatically handled by Claude;
Overall accuracy is approximately 95%.

https://claude.com/blog/how-anthropic-enables-self-service-data-analytics-with-claude?utm_source=chatgpt.com
This blog directly targets the core pain point of AI-driven data queries: answers that look correct but inspire no real confidence, hiding potential landmines beneath the surface.
Anthropic has even coined a term for this phenomenon: "false sense of precision."
When Claude is directly connected to a data warehouse and left to run autonomously, it may return a well-formatted, confidently worded response—but quietly using the wrong table.
The author of this blog comes from Anthropic’s Data Science and Data Engineering team. After offloading repetitive, mechanical data extraction tasks to Claude, they freed up time to focus on causal modeling, forecasting, and machine learning.
One of the most counterintuitive insights they highlight is this: the hardest part of making models accurately retrieve data isn’t writing SQL.
Structured Query Language (SQL) is the language used to extract data from databases—historically, proficiency in SQL was a gatekeeper for data analysis.
But for today’s large models, translating natural language into SQL is no longer the bottleneck. The real difficulty lies not in writing SQL, but in what comes before it.
Three Common Errors: Data Itself Is a Mess
Anthropic argues that the core challenge in data analysis lies in the fact that data itself is a “messy ledger.”
For the same question, multiple seemingly similar datasets often exist—yet it’s unclear which one should be used.
What AI must actually do is identify the correct dataset among this pile. Once that step is done correctly, extracting the data via SQL becomes nearly trivial.
Anthropic identifies the primary causes of model errors in data analysis as falling into three categories.

The true difficulty for analytical AI is mapping user questions to the correct and most up-to-date data entities.
First category: conceptual mismatch with data entities.
A single data model may contain hundreds of fields that appear usable, each potentially backed by millions of underlying records. When asked “How many active users?”—what constitutes activity? Are fraud accounts included? Should the lookback window be 7 or 30 days? The model struggles to pick the right option from a set of near-synonyms.
Second category: outdated data.
Data sources, business definitions, and table schemas evolve daily. As the model's knowledge gradually “rusts,” it begins returning answers with subtle errors. These are the hardest to detect—everything looks correct, yet the truth has already shifted.
Third category: retrieval failure.
The relevant information is present within the model’s knowledge base and fully annotated. Yet due to an overly large search space, the model simply fails to find it.
Comparing this to code generation highlights the difference clearly. Writing code is an open-ended task, where documentation and unit tests naturally guard against hallucination. In data analysis, there is typically only one correct answer and one correct source—and no deterministic way to prove it’s correct.
Thus, Anthropic concludes: accuracy in analysis is not about whether the model can write code—it’s about context and validation.
From 21% to 95%: What Anthropic Did in Between
To address these three error types, Anthropic built a system called the Agentic Analytics Stack—a four-layer architecture, each layer targeting a specific problem.

Anthropic’s Agentic Analytics Stack Architecture: Four layers—Data Foundations, Sources of Truth, Skills, and Validation—each with distinct responsibilities.
First layer, Data Foundations: The data warehouse itself, including data models, transformations, tests, tables, and associated metadata. The core action here is consolidating a single concept into one authoritative table—directly addressing “concept-entity ambiguity”—while also establishing the first engineering defense line against outdated data definitions.
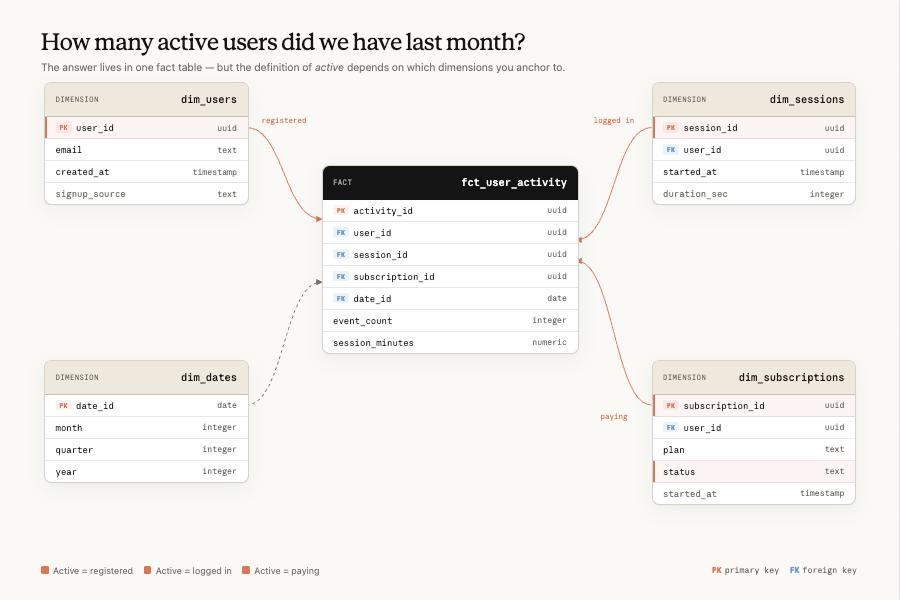
Anthropic emphasizes that traditional data engineering practices like dimensional modeling remain critical in the AI era.
Second layer, Sources of Truth: A set of authoritative references the model consults when retrieving data. Ordered by trustworthiness: semantic layer > lineage and transformation graph > query corpus > business context. Its purpose is to translate ambiguous user phrasing into a single, well-maintained, system-level data definition.
Together, the first two layers specifically target the “concept misalignment” problem.
Third layer, Skills: Codifying veteran analysts’ query workflows into reusable modules—this layer addresses “retrieval failure” and ensures the model reliably finds and uses the correct answer.
Fourth layer, Validation: Offline evaluation, ablation studies, online validation, and maintenance processes—all designed to detect which error types persist despite prior fixes, serving as the primary mechanism to combat “data obsolescence.”
In building these layers, Anthropic encountered two counterintuitive findings.
First: the cost of laziness.
They experimented with letting the large model automatically generate metric definitions from raw tables—but the resulting definitions merely encoded the original ambiguities back in, leading to negative scores in evaluations. Ultimately, they reverted to the old method: Claude drafts documentation, and human experts finalize definitions.
The second finding was even more surprising. Feeding thousands of historical SQL queries directly into the model for retrieval improved accuracy by less than 1 percentage point.
The largest accuracy leap revealed by Anthropic came from the Skills layer.
Sources of Truth represent declarative knowledge—telling the model what each metric means; Skills represent procedural knowledge—guiding the model on which query to run first, in what sequence, and what a valid analysis should look like.
Formally, Skills are a folder containing SKILL.md, instructions, scripts, and resources—read dynamically by Claude as needed. This mechanism is cross-verified in both Anthropic’s official documentation and GitHub repositories.
How impactful is it?

According to internal metrics disclosed by Anthropic, without Skills, Claude’s accuracy in internal evaluations never exceeded 21%. With Skills added, accuracy consistently soared above 95%, reaching nearly 99% in certain domains.
The jump from 21% to 95% wasn’t due to a stronger model—it was due to this architectural design.
Beyond 95%: This System “Decays” Over Time
Yet the 95% accuracy didn’t last long.
Anthropic discovered that the system ages: they watched offline accuracy drop from around 95% to roughly 65% within just one month.
The root cause? Data models change daily. Skill documentation, however, remained unmanaged—so after a few weeks, the system began producing incorrect responses.
Thus, Anthropic treated maintenance as a proper engineering discipline: integrating Skill documentation and data models into the same code repository. Every code merge request (PR) that modifies a data model now includes a corresponding update to its Skill documentation. Today, about 90% of data model changes are accompanied by a Skill update.
They also ran a negative experiment.
Giving the agent full-text search (grep) access to historical SQL files, and confirming in logs that it read every line—yet accuracy fluctuated by less than 1 point. Even worse, in cases where the model answered incorrectly, about 80% of correct answers were literally present in the very corpus it had just scanned. It saw them—but failed to use them.
At that moment, Anthropic realized: the real bottleneck isn’t access to data—it’s structure. This insight directly reshaped their roadmap for the next several months.
Getting the right structure lifts accuracy to a high level. But those final few percentage points come at a real cost.
For example, adding adversarial review—forcing the model to repeatedly challenge its own assumptions—boosts accuracy by another 6%, but at a cost of 32% higher token usage and 72% increased latency.
95% isn’t built—it’s cultivated. Let go for just a few weeks, and it collapses back down.
References:
https://claude.com/blog/how-anthropic-enables-self-service-data-analytics-with-claude
This article is originally from the WeChat public account “New Intelligence Yuan,” authored by ASI Revelation, published with authorization from 36Kr.
Source: 36Kr
Disclaimer: Contains third-party opinions, does not constitute financial advice
Dell's stock has surged 230% year-to-date, prompting Seeking Alpha to examine whether its valuation is overheated
23 mins ago
Technology stocks decline amid disappointing guidance from Broadcom and Ciena, with Broadcom's share price plunging 13%
28 mins agoGoogle Labs launches experimental app Dreambeans, generating personalized stories by integrating data from Gmail and other sources
31 mins agoApple's new Siri may run on Google Cloud's Nvidia Blackwell B200 GPUs
34 mins agoAnthropic Claude Mythos Technical Preview Breached Unauthorized Access, Security Infrastructure Emerges as Critical in AI Defense
40 mins agoNVIDIA Open-Sources 550B-Parameter Nemotron 3 Ultra Model with Hybrid Mamba-Transformer Mixture-of-Experts Architecture
45 mins agoSnap Acquires Augmented Reality Firm Illumix to Strengthen AR Technology Strategy
2 hours ago